并非是wp,而是做题过程中的一些记录
luck_guy
主函数
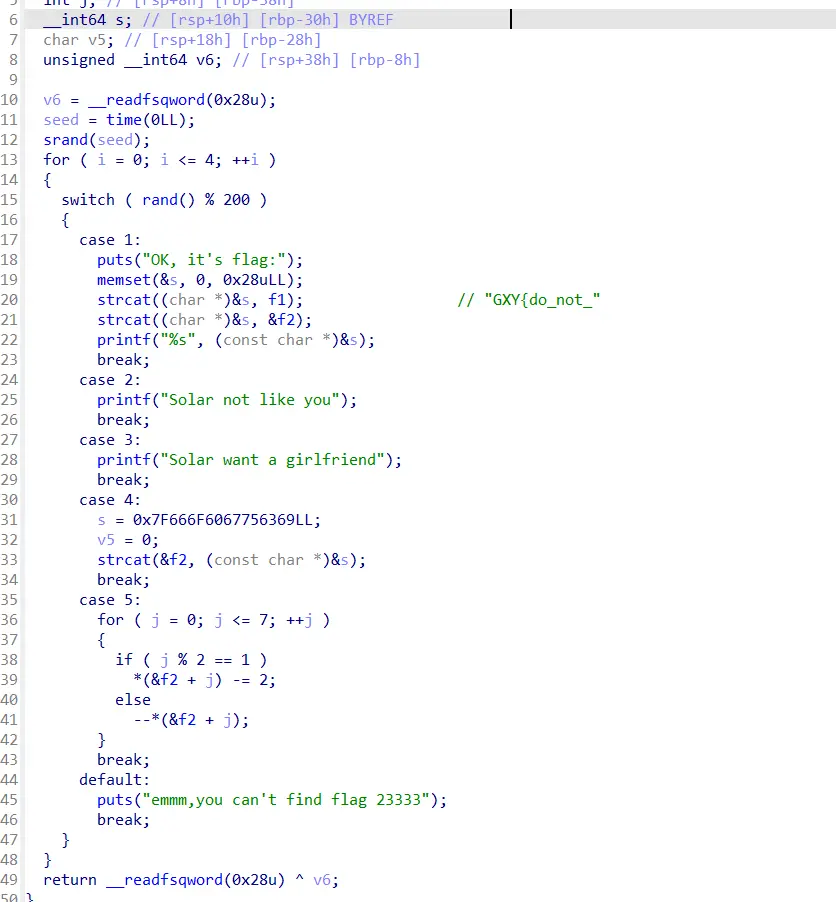
- ①.Case2 和 case3 只是一个打印函数。
- ②.strcat 是连接字符串函数,所以 case4 是对 s 赋值并将 s 与 f2 进行拼接。
- ③.case5 是对 f2 进行处理:j 为奇数,f2 减 2;j 为偶数,f2 减 1。
- ④.Case1 是要得到 flag,首先memset函数先对 s 进行初始化,s 变成了一个空数组,所以之后的 strcat 函数相当于直接把 f1 复制到了 s 里,再之后的 strcat 函数将 s 与 f2 连接相当于 f1 与 f2 连接,最终打印出来的 flag 就是 f1 加上 f2。
s=0x7F666F6067756369LL,按r键将它转换为字符就是“\x7Ffo`guci”,这里要注意是小端序存储!所以要把字符顺序反过来,就是“icug`of\x7F”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#include <iostream>
using namespace std;
int main()
{
char f2[] = "icug`of\x7F";
for (int j = 0; j < 8; ++j)
{
if ( j % 2 == 1 )
f2[j]-=2;
else
f2[j]--;
}
printf("%s",f2);
return 0;
}
|
刮开有奖
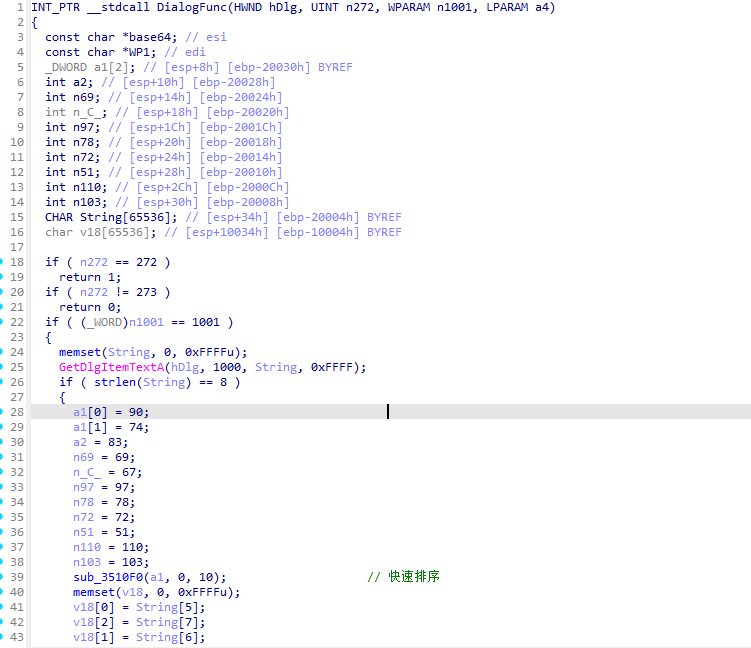
加密逻辑其实挺清晰的一道题,快速排序+base64编码,快速排序这里不懂的话可以去问ai,不过还是要自己判断,也可以把代码复制下来在vscode中运行一遍看看结果
但是第一次疑惑的地方是加密排序那个数组a1只初始化了两个数,但是它的结束索引却是十。这里学到的知识是:
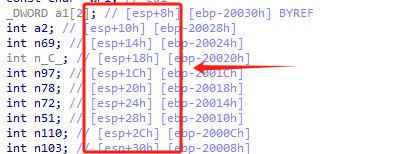
根据这段初始化,知道这段的地址是连续的。所以实际上是一个长度为11的数组,别问我为什么不动调,F9点开后调不了一点
然后就是
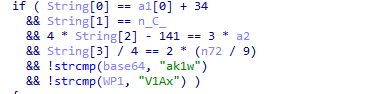
对比判断的时候这里用的是地址处的值也就是说是排序后的值
然后要提一嘴的是

具体可以去看这里
WinMain函数 (winbase.h)
WinMain 函数(Windows图形应用程序入口点)
1
2
3
4
5
6
|
int __clrcall WinMain(
[in] HINSTANCE hInstance,
[in, optional] HINSTANCE hPrevInstance,
[in] LPSTR lpCmdLine,
[in] int nShowCmd
);
|
参数:
hInstance:当前应用程序实例的句柄。
hPrevInstance:上一个实例的句柄(在现代Windows中始终为NULL)。
lpCmdLine:命令行参数,不包括程序名称。
nShowCmd:控制窗口显示方式的标志。
返回值:程序的退出状态码,通常返回 WM_QUIT 消息的 wParam 参数值。
easyre
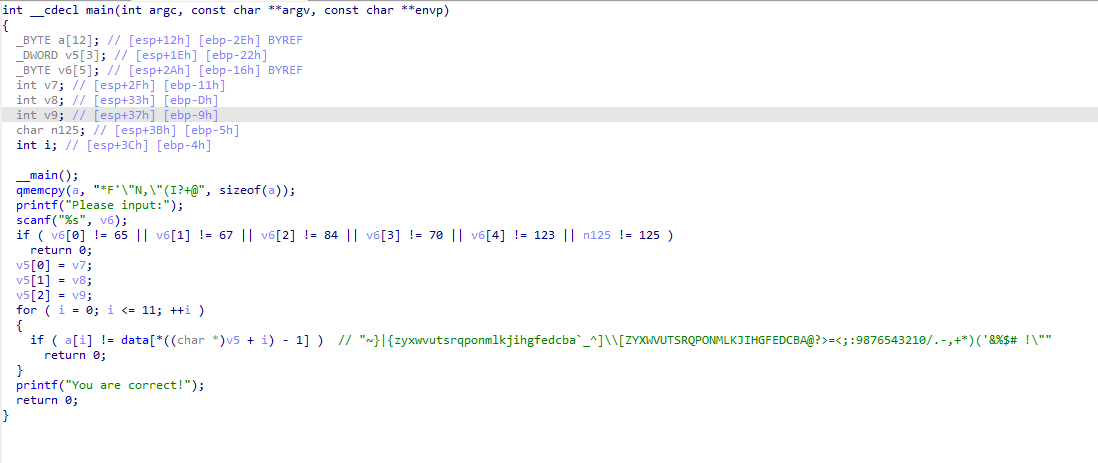
脱壳后的主函数
分析比较语句,大致猜到v5就是输入的函数,这里的意思是输入字符的ascii值+1后作为索引进行判断
- python中的find()函数是找到对应的下标值
1
2
3
4
5
6
7
8
9
10
11
12
|
U
U9
U9X
U9X_
U9X_1
U9X_1S
U9X_1S_
U9X_1S_W
U9X_1S_W6
U9X_1S_W6@
U9X_1S_W6@T
U9X_1S_W6@T?
|
[GUET-CTF2019]re
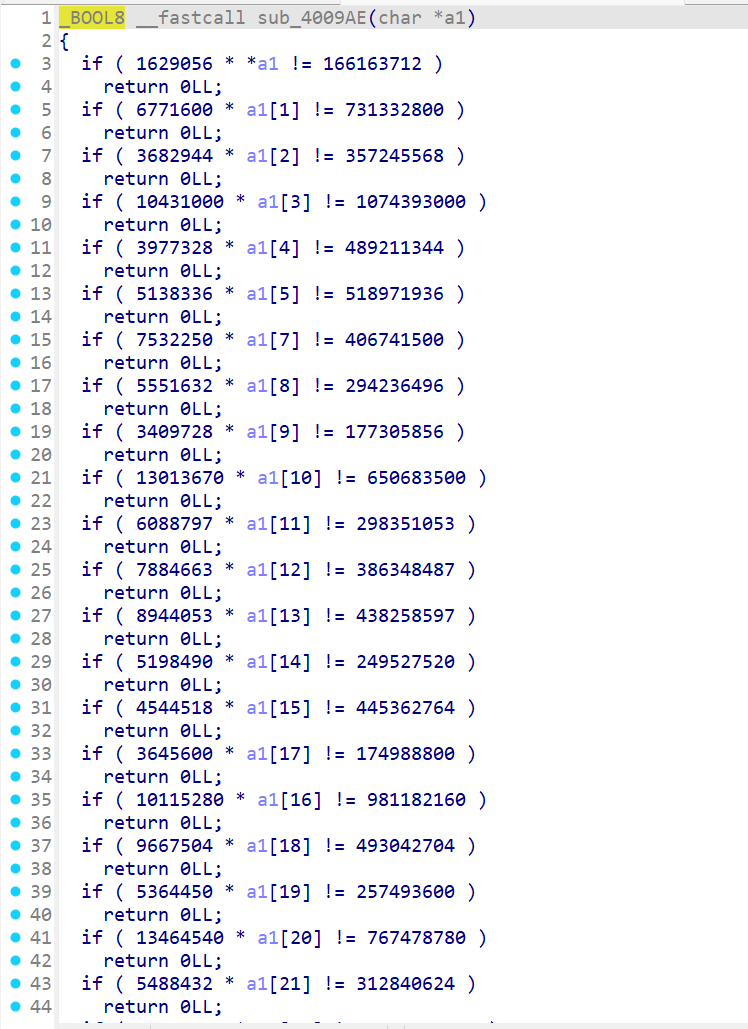
考z3处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
from z3 import *
solver = Solver()
# 使用Int类型而非BitVec,并添加字符范围约束
a1 = [Int(f'a1_{i}') for i in range(32)]
# 添加所有等式约束
solver.add(1629056 * a1[0] == 166163712)
solver.add(6771600 * a1[1] == 731332800)
solver.add(3682944 * a1[2] == 357245568)
solver.add(10431000 * a1[3] == 1074393000)
solver.add(3977328 * a1[4] == 489211344)
solver.add(5138336 * a1[5] == 518971936)
solver.add(7532250 * a1[7] == 406741500)
solver.add(5551632 * a1[8] == 294236496)
solver.add(3409728 * a1[9] == 177305856)
solver.add(13013670 * a1[10] == 650683500)
solver.add(6088797 * a1[11] == 298351053)
solver.add(7884663 * a1[12] == 386348487)
solver.add(8944053 * a1[13] == 438258597)
solver.add(5198490 * a1[14] == 249527520)
solver.add(4544518 * a1[15] == 445362764)
solver.add(3645600 * a1[17] == 174988800)
solver.add(10115280 * a1[16] == 981182160)
solver.add(9667504 * a1[18] == 493042704)
solver.add(5364450 * a1[19] == 257493600)
solver.add(13464540 * a1[20] == 767478780)
solver.add(5488432 * a1[21] == 312840624)
solver.add(14479500 * a1[22] == 1404511500)
solver.add(6451830 * a1[23] == 316139670)
solver.add(6252576 * a1[24] == 619005024)
solver.add(7763364 * a1[25] == 372641472)
solver.add(7327320 * a1[26] == 373693320)
solver.add(8741520 * a1[27] == 498266640)
solver.add(8871876 * a1[28] == 452465676)
solver.add(4086720 * a1[29] == 208422720)
solver.add(9374400 * a1[30] == 515592000)
solver.add(5759124 * a1[31] == 719890500)
# 确保每个字符在0-255范围内(ASCII)
for c in a1:
solver.add(c >= 0, c <= 255)
if solver.check() == sat:
model = solver.model()
flag = ''.join([chr(model[c].as_long()) for c in a1]) # type: ignore
print("", flag)
else:
print("无解")
# flag{e65421110ba03099a1c039337}
|
但是疑惑的是少了一位,最后看别人题解都是爆破出来的(,a1[6]=‘1’,
所以正确的应该是flag{e165421110ba03099a1c039337}
CrackRTF
这道题的考点是rtf文件,主要的逻辑是先输入六个数字拼接@DBApp然后判断hash-sha1编码,这里爆破出的结果是123321,然后是长度为6的字符串,拼接在一起进行MD5编码,由于MD5编码不可逆,我尝试过爆破,生成所有 6 位组合,总数为 95^6 ≈ 735 亿次,遂放弃。
RTF是Rich Text Format的缩写,意即多文本格式。
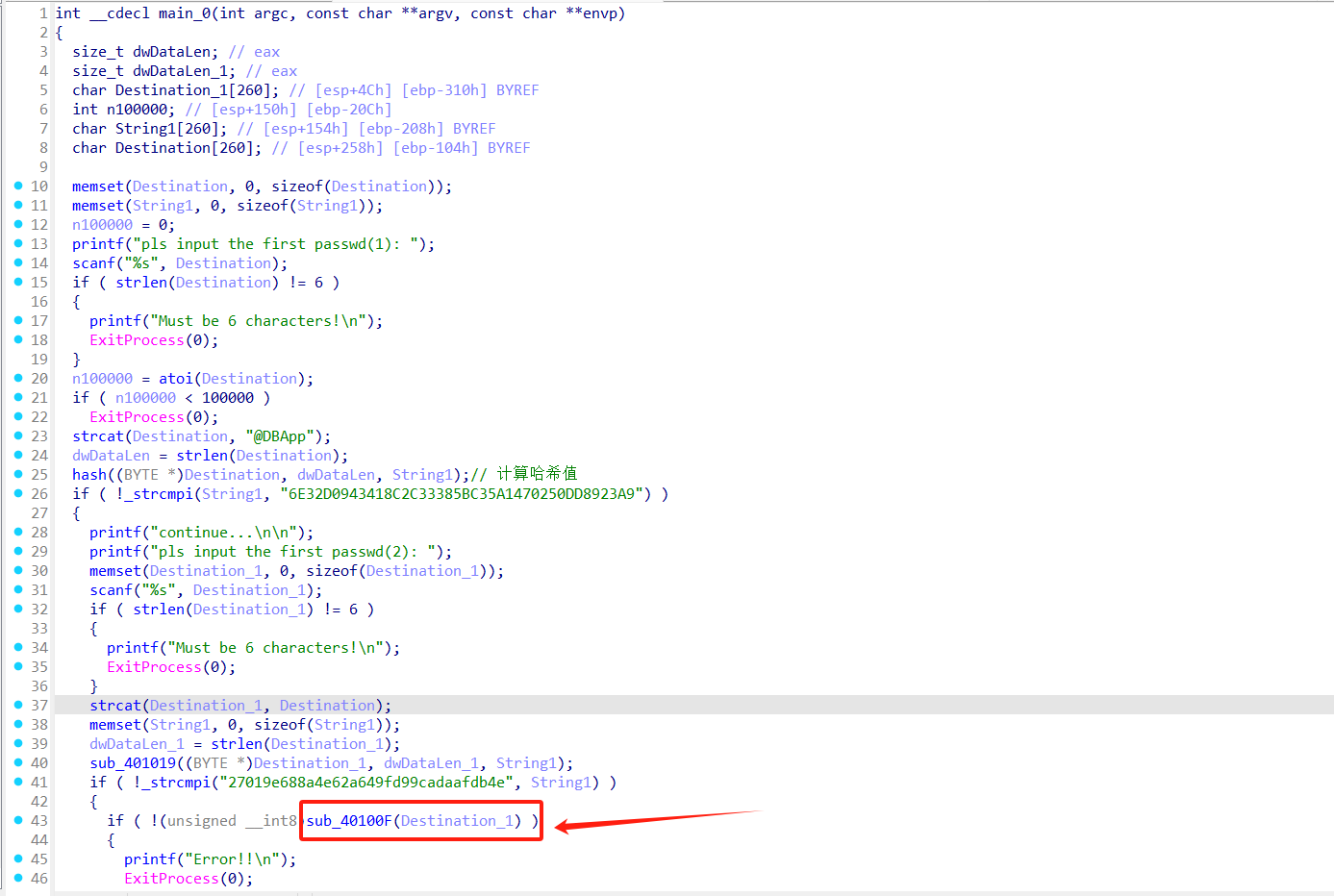
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
char __cdecl sub_4014D0(LPCSTR Destination)
{
LPCVOID lpBuffer; // [esp+50h] [ebp-1Ch]
DWORD NumberOfBytesWritten; // [esp+58h] [ebp-14h] BYREF
DWORD nNumberOfBytesToWrite; // [esp+5Ch] [ebp-10h]
HGLOBAL hResData; // [esp+60h] [ebp-Ch]
HRSRC hResInfo; // [esp+64h] [ebp-8h]
HANDLE hFile; // [esp+68h] [ebp-4h]
hFile = 0;
hResData = 0;
nNumberOfBytesToWrite = 0;
NumberOfBytesWritten = 0;
hResInfo = FindResourceA(0, (LPCSTR)0x65, "AAA");// FindResourceA 函数用于查找程序资源中的一个资源。
// 第一个参数为 NULL,表示查找当前进程的资源。
// 第二个参数为资源标识符,这里是 0x65。
// 第三个参数为资源类型,这里是 "AAA"。
if ( !hResInfo )
return 0;
nNumberOfBytesToWrite = SizeofResource(0, hResInfo);// SizeofResource 函数用于获取资源的大小。
// 如果资源大小为 0,表示资源无效。
hResData = LoadResource(0, hResInfo); // LoadResource 函数用于加载资源。
if ( !hResData )
return 0;
lpBuffer = LockResource(hResData); // LockResource 函数用于锁定资源,并返回资源的指针。
sub_401005(Destination, (int)lpBuffer, nNumberOfBytesToWrite);// 异或
hFile = CreateFileA("dbapp.rtf", GENERIC_ALL, 0, 0, CREATE_ALWAYS, FILE_READ_ATTRIBUTES, 0);// CreateFileA 函数用于创建或打开一个文件。
// 文件名为 "dbapp.rtf"。
// 打开模式为 CREATE_ALWAYS,表示如果文件不存在则创建,如果存在则覆盖。
// 文件访问权限为 GENERIC_ALL,表示完全访问权限。
if ( hFile == (HANDLE)-1 ) // 如果文件创建失败,返回 0。
return 0;
if ( !WriteFile(hFile, lpBuffer, nNumberOfBytesToWrite, &NumberOfBytesWritten, 0) )
return 0;
CloseHandle(hFile); // 关闭文件句柄。
return 1;
}
|
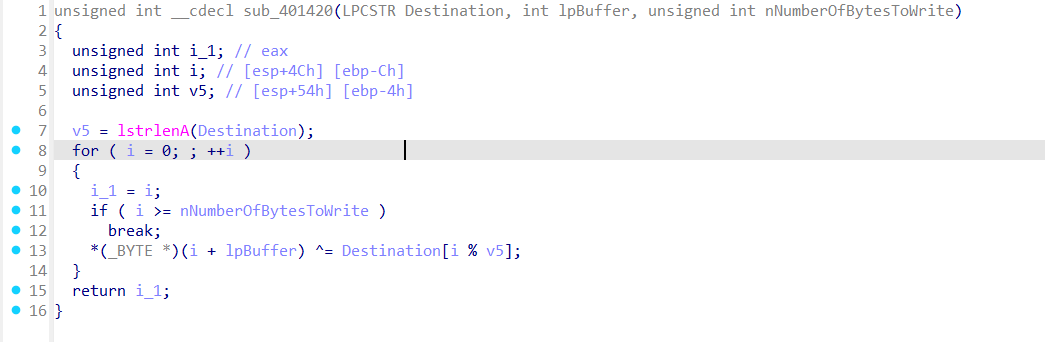
这里就是我们输入的东西拼接后与“AAA”文件中的读取的前几位异或
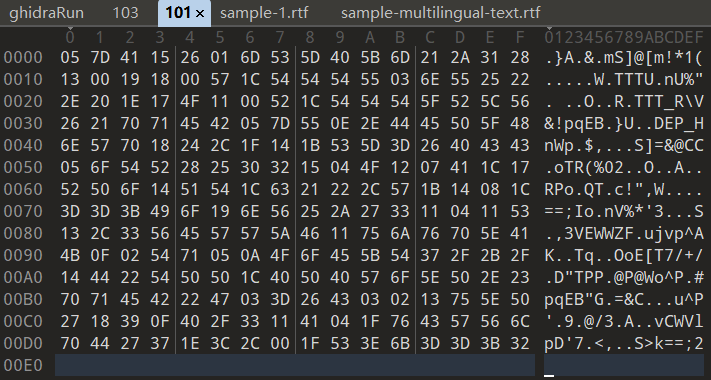
从网上找到rtf的示例文件下下来对比发现前几位都是一样的
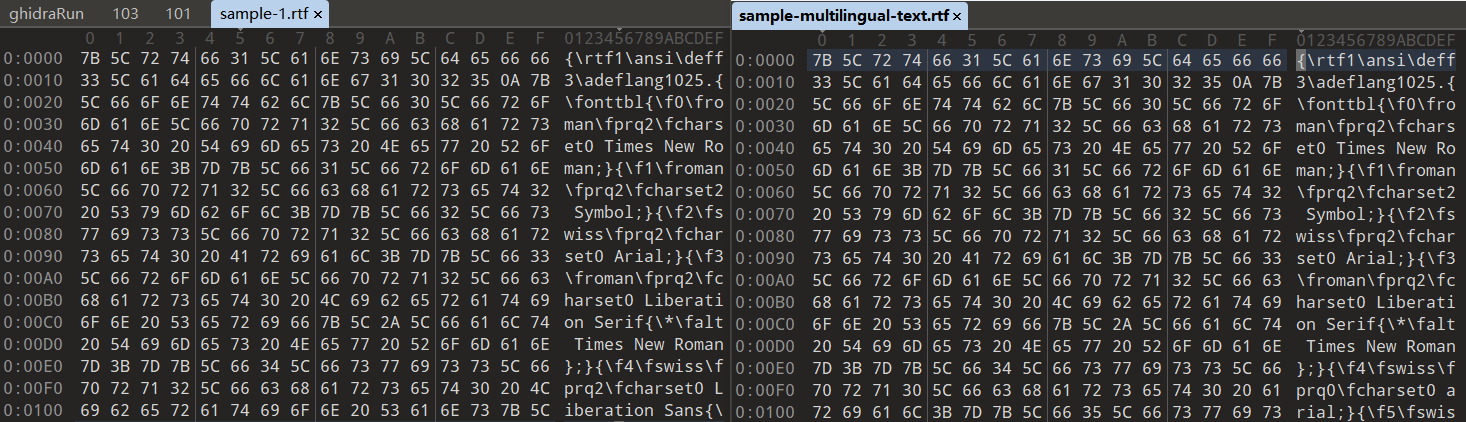
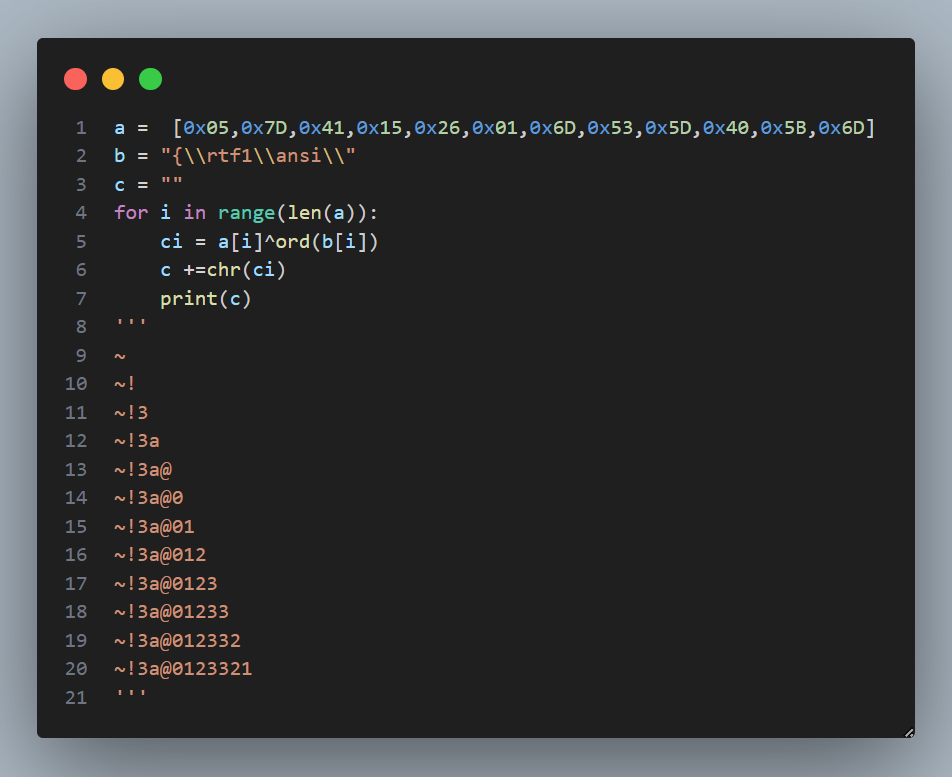
把前几位截下来,然后进行异或处理就能得到前六位~!3a@0123321,很明显**~!3a@0**为所求。于是在ida中动调,生成rtf文件,打开后得到flag
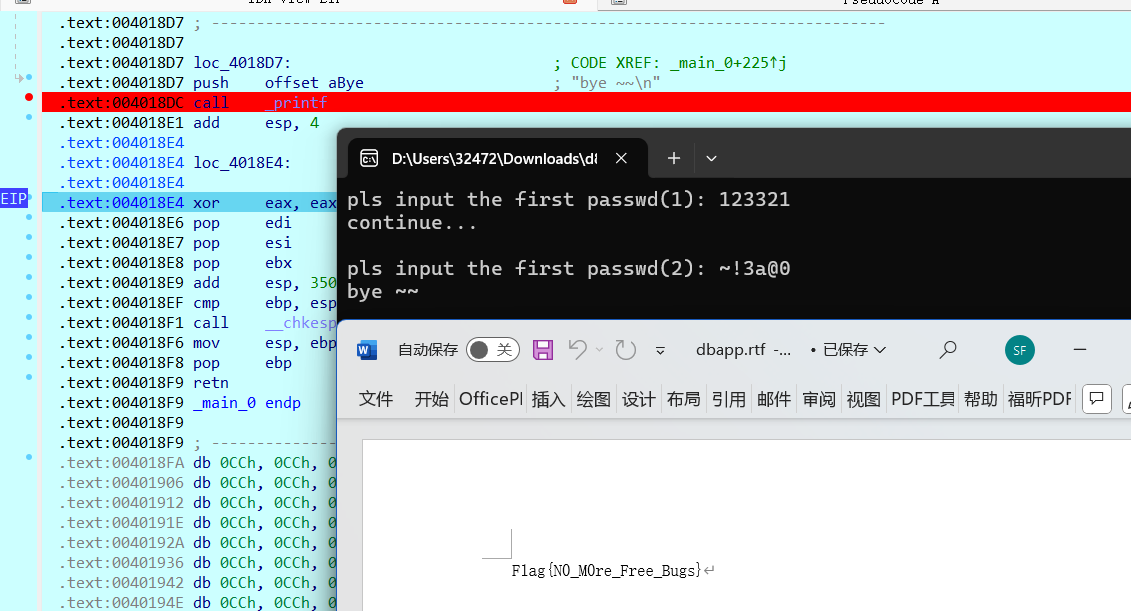
ezpy.exe
1. 初始侦察 (Initial Reconnaissance)
拿到题目文件 ezpy.exe 后,首先需要确定其文件类型。
- 查壳/识别: 这是一个 Windows 可执行文件。通常 Python 逆向题目都是由 PyInstaller 或 py2exe 打包的。
- 特征: 文件图标、字符串信息通常会暴露它是 PyInstaller 打包的。
- 解包: 使用工具
pyinstxtractor.py 对 ezpy.exe 进行解包。
1
|
python pyinstxtractor.py ezpy.exe
|
解包后得到 ezpy.exe_extracted 文件夹。
2. Python 层分析 (Python Layer Analysis)
在解包后的文件夹中,寻找入口点。通常与 EXE 同名的 .pyc 文件是入口脚本。
- 目标文件:
ezpy.pyc
- 版本识别: 检查文件头 Magic Number 为
3571,确认为 Python 3.13。
2.1 反编译挑战
尝试使用传统的 uncompyle6 或 decompyle3 失败,原因如下:
- 版本过新: 这些工具主要支持到 Python 3.8/3.9,无法解析 Python 3.13 的新指令集(如
CACHE, RESUME 等)。
- 工具报错: 强制运行会抛出 Magic Number 不匹配或 Crash。
2.2 字节码分析方案
针对高版本 Python,我们采用了以下两种有效方案:
方案 A:使用 xdis 库的 pydisasm (推荐)
如果环境中安装了 xdis (pip install xdis),可以直接使用 pydisasm 命令,它对多版本 Python 支持极好。
方案 B:使用 Python 内置 dis 模块 (原生)
利用当前环境的 Python 3.13 解释器,编写脚本手动反汇编。这是最准确的方法。
1
2
3
4
5
|
import marshal, dis
with open("ezpy.pyc", "rb") as f:
f.seek(16) # 跳过 16 字节文件头
code = marshal.load(f)
dis.dis(code)
|
2.3 逻辑还原
通过分析反汇编输出(关键指令如下):
IMPORT_NAME (mypy): 导入扩展模块。LOAD_GLOBAL (input) + CALL: 获取输入。LOAD_GLOBAL (check) + CALL: 调用 mypy.check()。POP_JUMP_IF_FALSE: 根据检查结果跳转分支。
还原后的 Python 源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
try:
from mypy import check
except ImportError:
print('Error: Cannot import mypy module')
exit(1)
def main():
user_input = input('Please input your flag: ').strip()
if check(user_input):
print('Correct!')
else:
print('Wrong!')
if __name__ == '__main__':
main()
|
结论:核心校验逻辑下沉到了 mypy 模块中。在解包目录中找到了 mypy.cp313-win_amd64.pyd,这是一个 C++ 编写的 Python 扩展(本质是 DLL)。
3. Native 层分析 (C Extension Analysis)
使用 IDA Pro (或通过 MCP 连接) 分析 mypy.cp313-win_amd64.pyd。
3.1 定位关键函数
Python 扩展通常导出一个初始化函数 PyInit_mypy。
- 找到
PyInit_mypy。
- 查看其返回的
PyModuleDef 结构体。
- 在
PyModuleDef 中找到 m_methods (方法表)。
- 方法表中包含模块导出的函数名和对应的 C 函数地址。
- 发现导出函数
"check" 对应地址 0x36F4D1519 (偏移地址)。
3.2 分析 check 函数 (sub_36F4D1519)
反编译该函数,逻辑如下:
- 参数解析: 接收一个字符串参数。
- 长度检查: 检查输入长度是否为 25。
- 密钥准备: 代码中硬编码了字符串
"ISCTF2025"。
- 加密算法: 调用了一个子函数
sub_36F4D149C。
- 分析该子函数,发现典型的 RC4 算法特征(256次循环初始化 S 盒,异或交换)。
- 密钥为
"ISCTF2025"。
- 比较逻辑:
- 将用户输入经过 RC4 加密后的密文,与全局变量
byte_36F4D4050 处的字节数组进行逐字节比较。
我们需要提取用于比较的密文数据。
- 目标地址:
0x36F4D4050
- 数据长度: 25 字节 (由输入长度限制推断)。
- 提取困难: 在动态调试或 MCP 工具受限(无法直接读取内存字节)的情况下,需要静态提取。
- 静态提取方法:
- 计算 RVA (相对虚拟地址):
0x36F4D4050 - 基址 0x36F4D0000 = 0x4050。
- 查看 PE 节表 (Section Table):
.rdata 节的虚拟地址 (Virtual Address) 通常包含此范围。- 计算文件偏移 (File Offset) = RVA - 节虚拟地址 + 节原始数据偏移 (PointerToRawData)。
- 编写脚本 (
inspect_pe.py) 读取文件并提取这 25 个字节。
提取到的密文 (Hex):
1d d5 38 33 af b5 51 f3 2c 6b 6e fe 41 24 43 d2 71 cf a4 4c e3 9a 9a b5 31
5. 解密 (Decryption)
RC4 是对称加密算法,加密和解密过程相同。
- 算法: RC4
- 密钥:
ISCTF2025
- 密文: 上述提取的 25 字节。
编写脚本 (solve_flag.py) 运行解密:
1
2
3
|
key = b"ISCTF2025"
ciphertext = [...] # 提取的数据
print(rc4(key, ciphertext))
|
最终 Flag: ISCTF{Y0U_GE7_7HE_PYD!!!}
总结 (Summary)
这是一道典型的 Python + C 扩展逆向题。
- 入口: PyInstaller 解包。
- 定位: 发现逻辑下沉到
.pyd (DLL)。
- 逆向: 识别标准加密算法 (RC4)。
- 数据: 从二进制文件中提取加密常量。
- 还原: 编写脚本解密。
